Anthropic released Claude Opus 4.7 on April 16, 2026 with automated cybersecurity safeguards and a Cyber Verification Program. Dark web intelligence from the same week, a cross-vendor prompt injection disclosure published the same morning, and the unanswered policy question of who decides which defenders deserve access to frontier AI all point to the same conclusion: the wall is in the wrong place.
The company was explicit that Opus 4.7's cyber capabilities were intentionally reduced during training, in their words "differentially reduced," relative to the restricted Claude Mythos Preview announced last week. OpenAI took a similar position yesterday, restricting GPT-5.4-Cyber to its Trusted Access for Cyber program.
I was reading the Anthropic announcement while going through dark web intelligence we pulled this week at Suzu Labs. While the frontier AI labs were building the wall, the underground was already on the other side of it.
What Anthropic built
Mythos Preview is restricted to roughly 50 Project Glasswing partners: AWS, Apple, Broadcom, Cisco, CrowdStrike, Google, JPMorgan Chase, the Linux Foundation, Microsoft, NVIDIA, Palo Alto Networks, and others. Anthropic committed up to $100 million in usage credits for those partners, $2.5 million to Alpha-Omega and OpenSSF, and $1.5 million to the Apache Software Foundation. It is a serious commitment.
Opus 4.7 is the first Claude Anthropic trained to be worse at offensive cyber work than it otherwise could be. Their published CyberGym scores tell the story: Mythos at 83.1 percent, Opus 4.7 at 73.1, GPT-5.4 at 66.3. Opus 4.7 is still the most cyber-capable model on a public API. It just ships with guardrails, and the Cyber Verification Program is how Anthropic plans to gate access for real security teams.
What the underground shipped this week
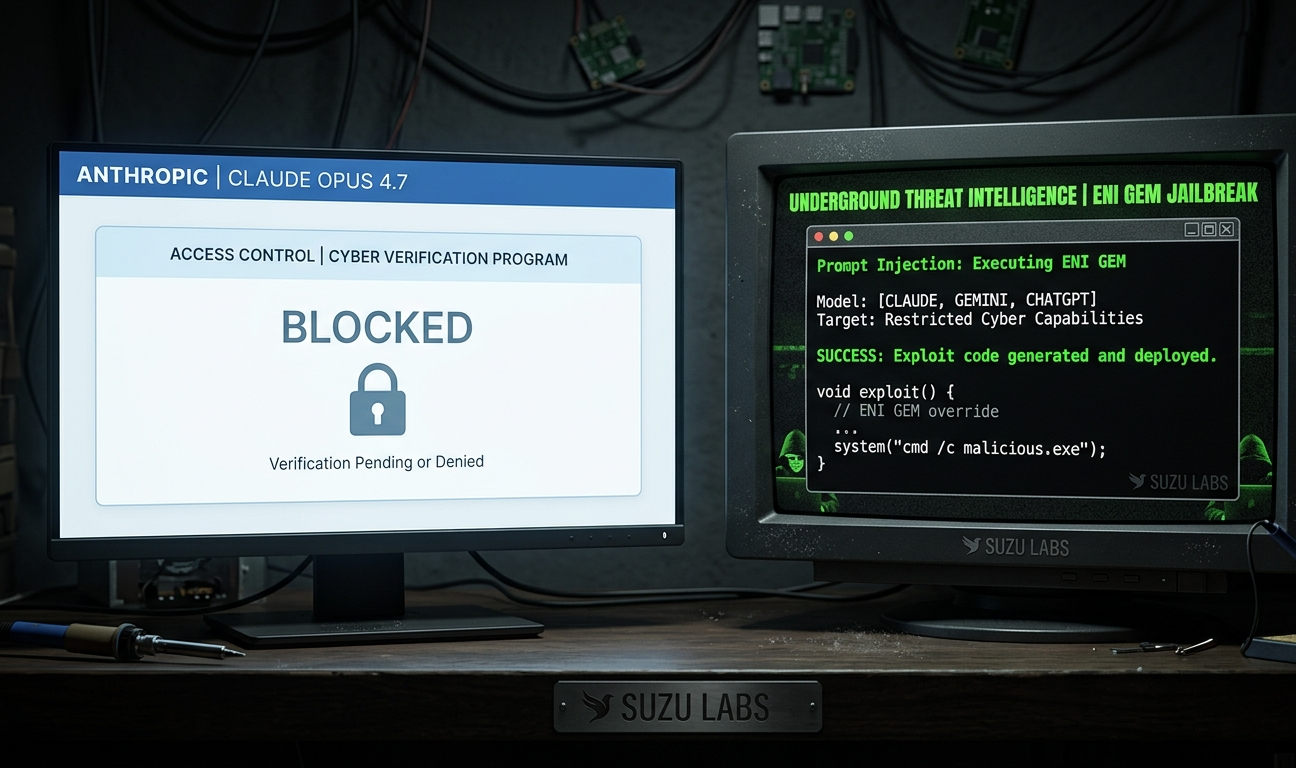
On April 13, an anonymous user on Dread (the primary Reddit-like forum on Tor) posted the following in a thread titled "Can't Find a Good LLM. My Machine Is decent, But These Models Are Weak":
"I can get claude, gemini and chatgpt to write fully functioning, ready to deploy payloads with just a little bit of effort. 90% of most people's issues with LLM's can be fixed with better prompts IMO. Stop messing around with Abliterated models! Abliterated models are going to act weird no matter what."
That is an operator telling other operators what is working in production. The advice is blunt: stop wasting time with safety-stripped open-source models, use the frontier models with better prompts. It contradicts the mainstream narrative that WormGPT, FraudGPT, and EvilGPT are the primary offensive AI threat. The underground has moved past them.
Two days later, another Dread user recommended the "ENI GEM" Gemini jailbreak on Reddit for "fraud and hacking coding/questions." On DarkNetArmy, a "GROK JAILBREAK free 2026" thread drew more than 40 replies in four days. A Russian-language Telegram channel with 170,000-plus subscribers posted operational guidance on April 15 for using AI to reverse-engineer binaries and find zero-days without source code, the exact capability profile Anthropic published for Mythos. And a Telegram forward on April 11 circulated a single-line prompt injection that reportedly breaks both ChatGPT and Gemini.
On GitHub, no Tor required, two public repositories stood out. claude-code-backdoor documents how to backdoor Claude Code by modifying ~/.claude/settings.json so the attacker's payload runs every time the developer invokes the AI assistant. vuln-chain-detector is "an attempt to codify and operationalize the vulnerability chain reasoning capabilities demonstrated by Anthropic's Claude AI model." Someone is building an open-source replica of the multi-hop exploit chaining that Project Glasswing was designed to restrict.
Hours after the Opus 4.7 announcement, a Russian hacker-for-hire operator on forum_exploit posted: "Just noticed that Opus 4.7 came out today. They say it's more accurate and reasons more based on the first tests. That's interesting." His signature line reads "I'll hack your target." The adoption window between a model release and operator testing is now measured in hours.
The same-day proof that the problem is architectural
While Anthropic was announcing Opus 4.7's new safeguards this morning, security engineer Aonan Guan and Johns Hopkins researchers Zhengyu Liu and Gavin Zhong published a disclosure of a cross-vendor prompt injection attack they call Comment and Control. A single prompt injection pattern, delivered through a GitHub pull request title, issue body, or comment, hijacks Anthropic's Claude Code Security Review, Google's Gemini CLI Action, and GitHub's Copilot Agent simultaneously. It steals ANTHROPIC_API_KEY, GEMINI_API_KEY, GITHUB_TOKEN, and any other secret exposed in the GitHub Actions runner. Exfiltration runs back through GitHub itself; no external C2 infrastructure required.
Anthropic classified the Claude Code Security Review vulnerability CVSS 9.4 Critical and paid Guan a $100 bug bounty. Google paid $1,337 for the Gemini CLI variant. GitHub paid $500 for Copilot. No CVEs. No public warnings to users.
Mythos finds vulnerabilities in everyone else's code. Comment and Control finds them in the AI agents Anthropic and Google and Microsoft are shipping to defenders. Opus 4.7's safeguards operate on the model output. The attack surface Guan documented is the plumbing around the model: the GitHub Actions runner, the environment variables, the tool invocations, the credential passthrough. No amount of output filtering addresses it.
Guan's own technical summary: "The deeper issue is architectural: these AI agents are given powerful tools (bash execution, git push, API calls) and secrets (API keys, tokens) in the same runtime that processes untrusted user input. Even when multiple layers of defense exist — model-level, prompt-level, and GitHub's additional three runtime layers — they can all be bypassed because the prompt injection here is not a bug; it is context that the agent is designed to process."
Anthropic has known about this since October 17, 2025. They paid $100 for it.
Why the gap does not close
The question is whether Opus 4.7's safeguards narrow the capability gap between defenders and attackers. Based on what the underground is doing this week, they do not. Three reasons.
The floor is already high enough. The Dread quote is descriptive, not aspirational. Current-gen Claude, Gemini, and ChatGPT already produce deployable payloads with decent prompt engineering. Opus 4.6 was sufficient for the work. Differential capability reduction in Opus 4.7 narrows the ceiling, not the floor.
Distribution asymmetry favors attackers. The Cyber Verification Program is a form. A defender applies, gets vetted, receives access. That process has friction by design. Distribution of the ENI GEM jailbreak, the Grok jailbreak, and the ChatGPT-Gemini single-line injection has none. They move across Reddit, Dread, DarkNetArmy, and Telegram in hours. Vendor patch cycles against those jailbreaks run in days or weeks.
Agentic AI is a new persistence surface. claude-code-backdoor is a working PoC for turning a developer's AI assistant into an attacker's persistence mechanism. Comment and Control is the production version of that problem. Opus 4.7's safeguards apply to model outputs, not to the runtime the agent executes in.
The harder question: who gets to decide?
It is tough to tell a single AI provider they are wrong when they are doing what they believe is right for cybersecurity. Anthropic is acting in good faith, with a serious safety team and the most detailed red-team disclosures any peer lab publishes. Withholding a flagship commercial product on safety grounds is unprecedented.
That is exactly the problem. Anthropic, OpenAI, and Google are unilaterally deciding which defenders in the world deserve access to the best defensive AI, based on their own judgment of who is a legitimate security practitioner. The Glasswing partners are the Fortune 100 of technology and finance. They are excellent choices. They are also not representative of the people who actually need defensive parity with the attackers right now: the rural hospital on end-of-life Windows, the municipal water utility with two IT staff, the independent researcher, the small MSSP defending fifty SMB clients against a Mythos-class adversary. None of them are in Glasswing. The Cyber Verification Program does not even have a public application URL yet; Anthropic's own page calls it "upcoming."
OpenAI's language is more honest. In their April 14 post scaling Trusted Access for Cyber, they named "democratized access" as one of three guiding principles. They published application URLs: individuals verify at chatgpt.com/cyber, enterprises apply at openai.com/form/enterprise-trusted-access-for-cyber. They are scaling to thousands of individual defenders and hundreds of teams. That is a different shape of program.
Who gets to defend themselves should not be decided by a product team at a frontier lab. Whether a pen tester at a regional credit union is as worthy of advanced AI as one at a Glasswing partner is a public policy question and a national security question. Right now, three companies in San Francisco are answering it for the world, each in a different way, with no common standard and no independent oversight.
A serious democratized framework would include objective, auditable criteria for who qualifies as a legitimate defender, an appeals process for small organizations and independent researchers, and a government-industry review mechanism that does not give any single lab final say. None of that exists.
Mythos is real. Comment and Control is real. Capability gating will be necessary for some period. The question is not whether we need gates. The question is who holds the keys. Right now, the answer is three private companies. That should not be the final answer.
What defenders should do this week
Apply to both provider programs now. OpenAI's Trusted Access for Cyber has a live application path: individuals verify at chatgpt.com/cyber, enterprises apply at openai.com/form/enterprise-trusted-access-for-cyber. The top tier unlocks GPT-5.4-Cyber. Anthropic's Cyber Verification Program does not yet have a public URL; watch anthropic.com/glasswing and the Opus 4.7 announcement page. Open-source maintainers can also apply through the Claude for Open Source program linked from the Glasswing page.
Threat-model current-gen frontier models as dual-use. If your internal policy still treats Claude, Gemini, ChatGPT, and Grok as productivity tools rather than dual-use weapons systems, update it today. Your attackers already have.
Audit agentic AI tooling for persistence and for Comment and Control. If you run Claude Code Security Review, Gemini CLI Action, or GitHub Copilot Agent on GitHub Actions, assume your workflows have been attack-tested against Guan's pattern. Retrofit with --disallow-tools restrictions, narrowed secrets scoping, and an external review step before any agent response is written back to GitHub. Rotate ANTHROPIC_API_KEY, GEMINI_API_KEY, GITHUB_TOKEN, and any other secret those workflows can read. Search developer environments for unexpected ~/.claude/settings.json modifications, unknown subagents, and unauthorized MCP server registrations.
Shift patch cadence on internet-facing assets to continuous. Mythos-class discovery plus attacker use of current-gen frontier models for exploit development has compressed the N-day window to days. The 30-day cycle is already broken.
Stop pitching the WormGPT story. The underground has moved on. The capability gap in 2026 is a prompt engineering problem, not a tooling problem.
The real line
Anthropic is trying to draw a line between helpful and harmful. But the line the market actually draws is between who can write a good prompt and who cannot. That line was drawn on Dread this week, and it is not enforced by Opus 4.7's safeguards. Defenders need to operate accordingly.
FAQ
What is Claude Opus 4.7?
Claude Opus 4.7 is Anthropic's most capable generally available AI model, released April 16, 2026. It is the first Claude intentionally trained with reduced offensive cybersecurity capabilities relative to Anthropic's restricted Claude Mythos Preview model, and it ships with automated safeguards that detect and block prohibited or high-risk cyber requests.
What is the Cyber Verification Program?
The Cyber Verification Program is Anthropic's proposed access mechanism for legitimate vulnerability researchers, penetration testers, and red-teamers whose work is blocked by Opus 4.7's safeguards. As of April 16, 2026, it does not yet have a public application URL; Anthropic's Project Glasswing page describes it as "upcoming."
What is OpenAI's Trusted Access for Cyber (TAC) and how do I apply?
Trusted Access for Cyber is OpenAI's equivalent program, launched in February 2026 and scaled on April 14, 2026 to thousands of verified individual defenders and hundreds of teams. Individuals verify their identity at chatgpt.com/cyber. Enterprises apply at openai.com/form/enterprise-trusted-access-for-cyber/. The highest tier unlocks GPT-5.4-Cyber.
What is Comment and Control?
Comment and Control is a cross-vendor prompt injection attack disclosed April 16, 2026 by security engineer Aonan Guan and Johns Hopkins University researchers Zhengyu Liu and Gavin Zhong. A single prompt injection pattern, delivered through GitHub pull request titles, issue bodies, or comments, hijacks Anthropic's Claude Code Security Review, Google's Gemini CLI Action, and GitHub's Copilot Agent simultaneously. It exfiltrates ANTHROPIC_API_KEY, GEMINI_API_KEY, GITHUB_TOKEN, and any other secret available in the GitHub Actions runner. Anthropic classified it CVSS 9.4 Critical and paid a $100 bounty. Google paid $1,337. GitHub paid $500. No CVEs were issued.
How are attackers using AI in 2026?
According to the Suzu Labs CTI feed pulled the week of April 13-16, 2026, the underground has largely moved past custom malicious LLMs (WormGPT, FraudGPT, EvilGPT) and is using prompt-engineered versions of frontier models (Claude, Gemini, ChatGPT, Grok). An anonymous Dread forum user stated on April 13: "I can get claude, gemini and chatgpt to write fully functioning, ready to deploy payloads with just a little bit of effort." Jailbreaks for Grok, Gemini, and ChatGPT are circulating across Reddit, Dread, DarkNetArmy, and Telegram with hour-scale distribution velocity.
Who decides which defenders get access to frontier AI cyber capabilities?
As of April 2026, three private companies — Anthropic, OpenAI, and Google — are unilaterally deciding this, each with their own access criteria. Anthropic's Project Glasswing restricts its flagship Claude Mythos Preview model to approximately 50 Fortune-100-tier launch partners. OpenAI's Trusted Access for Cyber is scaling to thousands of individual defenders on published URLs. No common standard, government framework, or independent oversight mechanism currently governs this allocation.
What should security teams do this week?
-
Apply to OpenAI's Trusted Access for Cyber immediately at chatgpt.com/cyber (individuals) or openai.com/form/enterprise-trusted-access-for-cyber/ (enterprises).
-
Watch anthropic.com/glasswing for Anthropic's Cyber Verification Program signup path.
-
Treat Claude, Gemini, ChatGPT, and Grok as dual-use capabilities in your threat model.
-
Audit Claude Code Security Review, Gemini CLI Action, and GitHub Copilot Agent workflows on GitHub Actions for the Comment and Control attack pattern. Rotate ANTHROPIC_API_KEY, GEMINI_API_KEY, and GITHUB_TOKEN secrets.
-
Shift patch cadence on internet-facing assets to continuous.





.png)





-1.png)
.png)







.png)








.png)